OpenAI argues that SWE-bench Verified no longer reflects real coding ability because the benchmark is allegedly contaminated.
It is now pushing SWE-bench Pro as tougher replacement.
Scores plunged from ~70% to ~23% on the newer benchmark,
The number that every major AI lab has been using to claim coding supremacy was just declared meaningless.
OpenAI published a post this week announcing that SWE-bench Verified, the go-to benchmark for measuring AI coding capabilities, is so riddled with flawed tests and training data leakage that it no longer tells you anything useful about whether a model can actually write software.
The benchmark works like this: Give an AI a real GitHub issue from a popular open-source Python project, ask it to fix the bug without seeing the tests, and check if its patch makes the failing tests pass without breaking anything else.
The cleanup worked well enough that every major lab started citing scores on it as proof of progress. When Anthropic launched Claude Opus 4 in May 2025, Decrypt reported that the model scored 72.5% on SWE-bench Verified, beating GPT-4.1’s 54.6% and Gemini 2.5 Pro’s 63.2%. It was the coding benchmark that mattered.
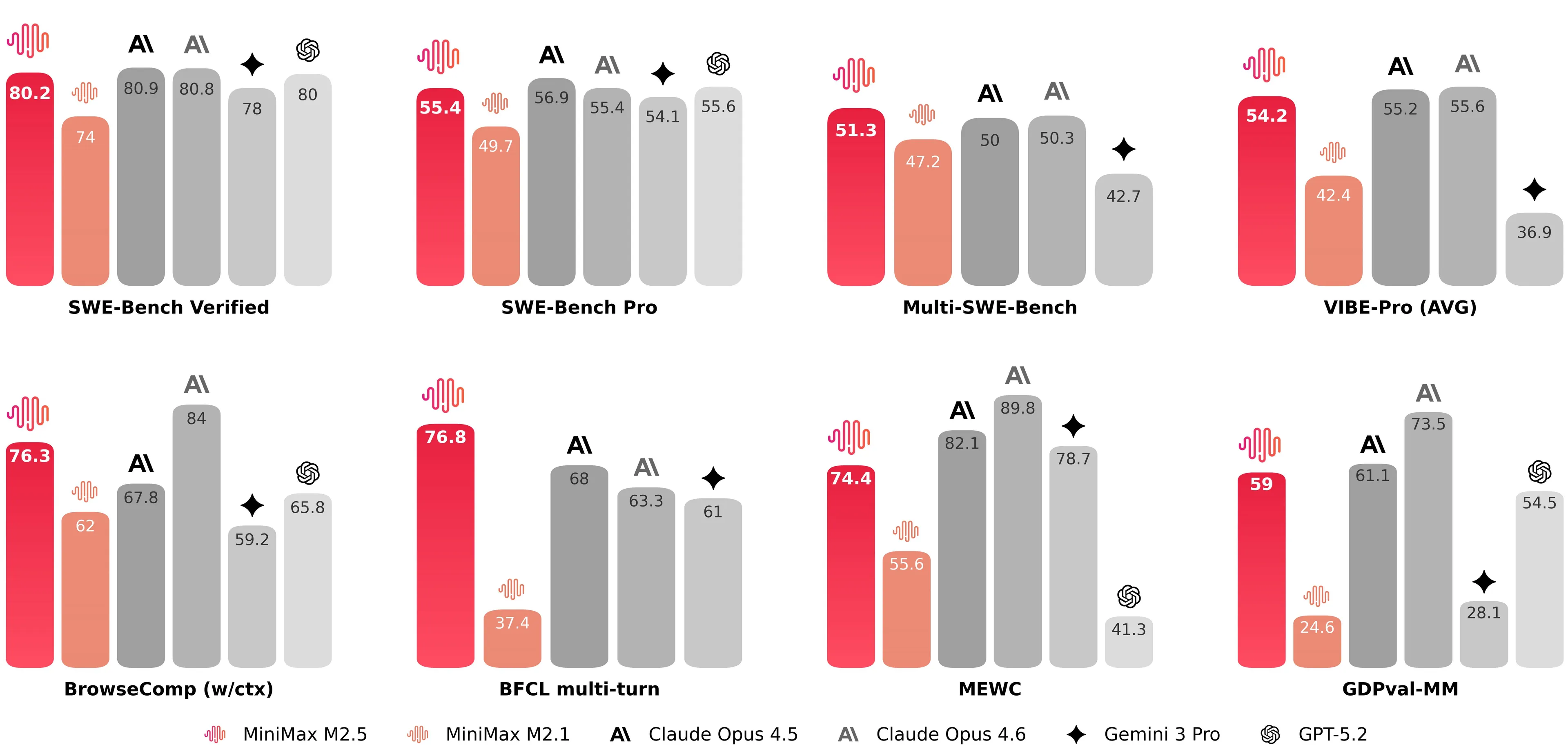
Since then, every single AI lab from America to China has shown the SWE performance to claim the throne as the best model for coding capabilities.
Image: Minimax
Now OpenAI says that race was partly a mirage. According to the report, the team audited 138 tasks that GPT-5.2 consistently failed across 64 independent runs, and had six engineers review each one. It ultimately concluded that 59.4% of those tasks are broken.
About 35.5% have tests so narrowly written that they require a specific function name never mentioned in the problem description. Another 18.8% check for features that weren’t part of the original problem at all, gathered from unrelated pull requests.
The contamination problem roughly works like this: SWE-bench pulls its problems from open-source repositories that most AI companies crawl when building training sets. OpenAI tested whether GPT-5.2, Claude Opus 4.5, and Gemini 3 Flash Preview had seen the benchmark’s solutions during training. All three had.
Given only a task ID and a brief hint, each model could reproduce the exact code fix from memory, including variable names and inline comments that appear nowhere in the problem description. In one case, GPT-5.2’s chain-of-thought logs showed it reasoning that a specific parameter must have been “added around Django 4.1″—a detail found only in Django’s release notes, not the task description. It was answering a question it had already seen the answer to.
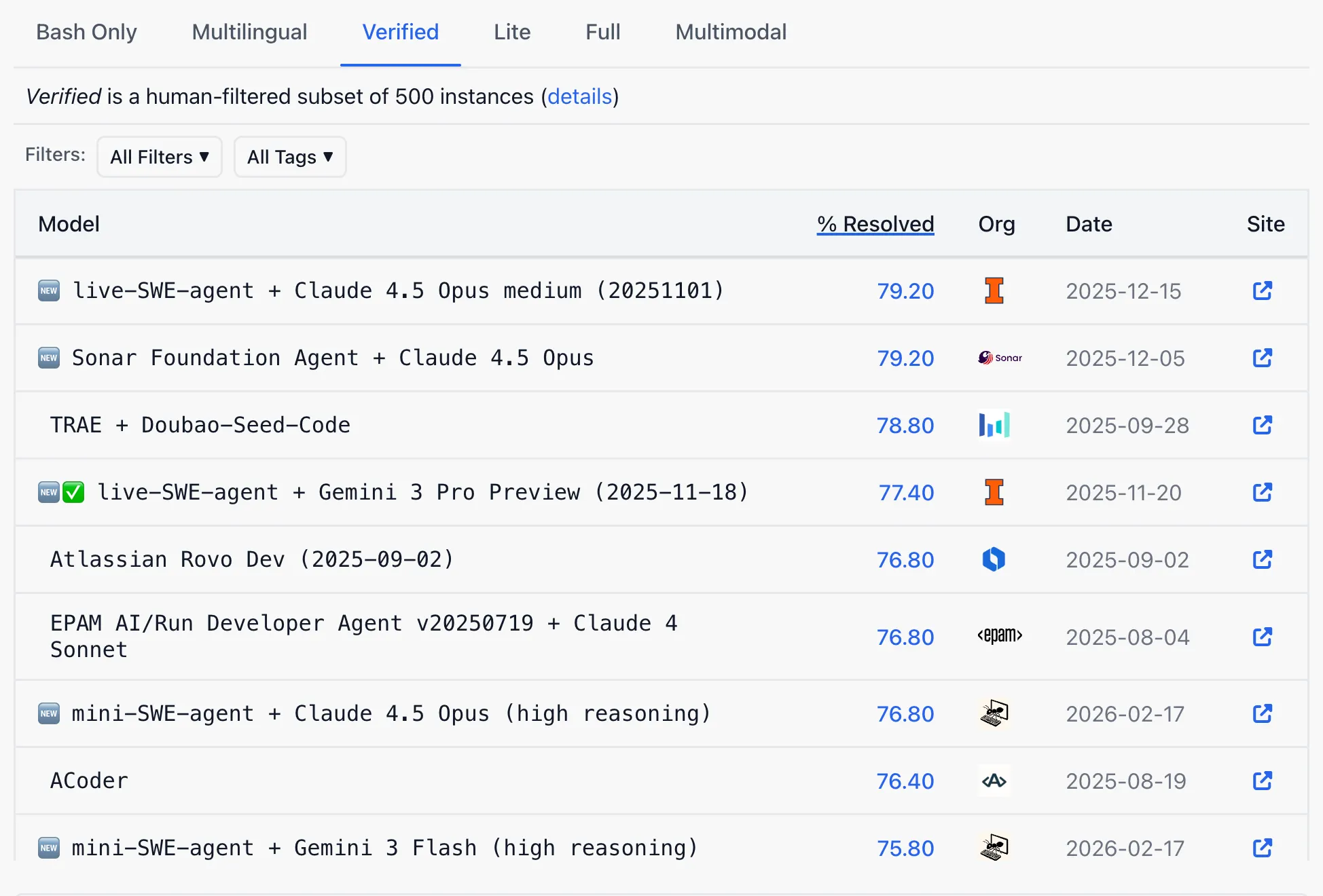
OpenAI now recommends SWE-bench Pro, a newer benchmark from Scale AI that uses more diverse codebases and licenses that reduce training data exposure. The performance drop is jarring: models that cleared 70% on the old Verified benchmark score around 23% on SWE-bench Pro’s public split, and even less on its private tasks.
On the current public SWE-bench Verified leaderboard, OpenAI is far from the benchmark’s podium. Retiring a benchmark where you’re losing and endorsing one where everyone starts at 23% resets the scoreboard at a convenient moment and makes the competitors’ claims less impressive.
This is especially important considering that the much anticipated newer version of DeepSeek is rumored to beat or get extremely close to American ai models, especially in agentic and coding tasks with a free, open-source model. That model could be days away from release, and SWE-bench Verified can be a key metric to measure its quality.
OpenAI said it’s building privately authored evaluations that won’t be released before testing, pointing to its GDPVal project where domain experts write original tasks graded by trained human reviewers.
The benchmark problem is not new, and is not unique to coding. AI labs have cycled through multiple evaluations, each useful until models were trained on them or until the tasks proved too narrow.
But what makes this case notable is that OpenAI hyped SWE-bench Verified, promoted it across model releases, and is now publicly documenting how thoroughly it has failed—including by showing their own model cheating on it.
Daily Debrief Newsletter
Start every day with the top news stories right now, plus original features, a podcast, videos and more.






















{kind=link}